
Java 컬렉션(Collections Framework)
- Java 컬렉션(Collection)은 데이터를 쉽고 효과적으로 처리할 수 있는 집합, 그룹을 뜻한다.
-> 데이터를 저장하는 자료구조와 처리하는 알고리즘을 구조화 하여 클래스화 시킨것이다.
- Java Interface 를 통해 구현된다.
- Collection의 상속 구조이다.
- Map 은 Collection이 아니지만 같이 묶어서 표현된다.
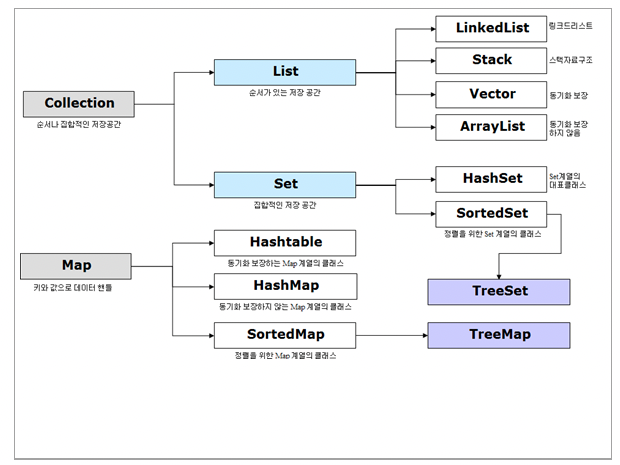
Collction Interface
| 인터페이스 | 구현 클래스 | 특징 |
| Set | HashSet(대표) TreeSet LinkedHashSet |
순서X, 데이터 중복X |
| List | ArrayList LinkedList Vector |
순서가 존재하고, 데이터의 중복을 허용 |
| Queue | LinkedList PriorityQueue |
List와 비슷, 선입선출(FIFO) 구조 |
| Map | HashMap TreeMap HashTable |
키(Key), 값(Value) 쌍으로 이루어진 구조, 순서X, 키(Key)의 중복을 허용 하지 않음. 다만 값(Value)중복은 허용 |
구현 클래스 - Detail
1. Set
- 순서가 보장되지 않으며(데이터를 index로 관리하지 않음.), 데이터가 중복될 수 없다.
1. HashSet (대표)
- Set 구현체 중 가장 대표적인 클래스이다.
- 접근속도가 제일 빠르다.
- 순서가 보장되지 않는다.
- 데이터 중복 불가.
2. TreeSet
- 저장된 데이터를 오름차순(ASC)으로 값을 정렬하여 저장.
- 순서가 보장되지 않음.(저장 순서로 저장되지 않음)
- 데이터의 중복 불가.
- 대량의 Data 검색시 빠름.
3. LinkedHashSet
- 저장된 순서대로 저장된다. (Set 중에 유일함.)
- 데이터 중복 불가
◎ Set 예제 - HashSet

2. List
- 순서가 존재하고, 데이터의 중복이 허용된다.
1. ArrayList
- 각 데이터에 대한 index를 가지고 있어, 조회 성능이 뛰어나다.
- 객체 추가시 크기가 부족하면 자동으로 부족한 크기만큼 용량을 증가시킨다.
- 사이즈가 고정되어 있으므로 중간에 데이터 삽입, 삭제가 빈번한 경우 LinkedList에 비해 효율이 좋지않다.
- 중간 데이터가 삭제될 시 해당 공백 인덱스에 뒷 데이터들을 재배치 해야함.
- 중간 데이터 삽입시, 인덱스 늘리고, 삽입위치를 기준으로 뒷데이터들을 뒤, 앞으로 이동 연산 후 삽입.
2. LinkedList
- 데이터의 삽입, 삭제가 빈번하게 이루어질 경우 사용하면 좋다.
- 각 노드가 다음 노드에 대한 정보(주소값)를 가지고 있어 검색 성능이 좋지않다.
- 순차 접근 (Sequential Access)만이 가능하기 때문이다.
- 각 노드는 다음 노드의 주소를 가지고 있을 뿐 데이터를 갖고 있는것이 아니기 때문이다.
3. Vector
- ArrayList와 동일한 구조를 사용한다.
- 자동으로 동기화 처리를 내부적으로 하기에 성능이 좋지않다.(스레드가 아닌 환경)
- 동기화라는 특징 때문에 스레드 환경에서 안정성은 높다.
- ArrayList와 비교하여 데이터의 삽입, 삭제, 검색 성능이 떨어지기 때문에 거의 사용하지 않는다.
◎ List 예제 - ArrayList

3. Map
- 키(Key), 값(Value)이 쌍으로 이루어져 있으며, 순서가 보장되지 않고, 키(key)값은 중복을 허용하지 않는다. 값(Value)은 중복을 허용한다.
1. HashMap (대표)
- 키, 값 1:1 구조로 이루어져 있다.
- Key값은 중복될 수 없다.
- Value값은 중복 될 수 있다.
- null 의 저장이 가능하다.
2. HashTable
- HashMap과 비슷하다.
- null 값 저장이 불가하다.
- HashMap 보다 속도가 느리다.
3. TreeMap
- 데이터 삽입시 오름차순으로 정렬되어 저장된다.
- 숫자 타입은 값으로 정렬, 문자열 타입은 유니코드로 정렬.
- HashMap 보다 전체적으로 성능이 좋지않다.
- 데이터의 저장, 삭제시 HashMap 보다 느리다.
- 정렬된 상태의 Map을 사용하거나, 정렬된 데이터를 조회해야 할 시 효율이 좋다.
◎ Map 예제 - HashMap

반응형
'Language > Java' 카테고리의 다른 글
| [Java] ThreadLocal이란? - (ThreadLocal, InheritableThreadLocal) 설명 및 예제(테스트) (0) | 2023.03.07 |
|---|---|
| [Java] Java 메모리 영역(stack, heap, static), JVM, JAVA 변수 종류 (2) | 2023.02.07 |
| [Java] Multi Thread를 이용한 간단 게임 구현(구구단) (0) | 2023.01.26 |
| [Java] Lombok 실제 사용법(2) (0) | 2023.01.17 |
| [Java] LomBok이란? & 어노테이션 정리 (1) (0) | 2023.01.17 |



댓글